GPU Programming in Python: CUDA Introduction
Why GPU? ⚡
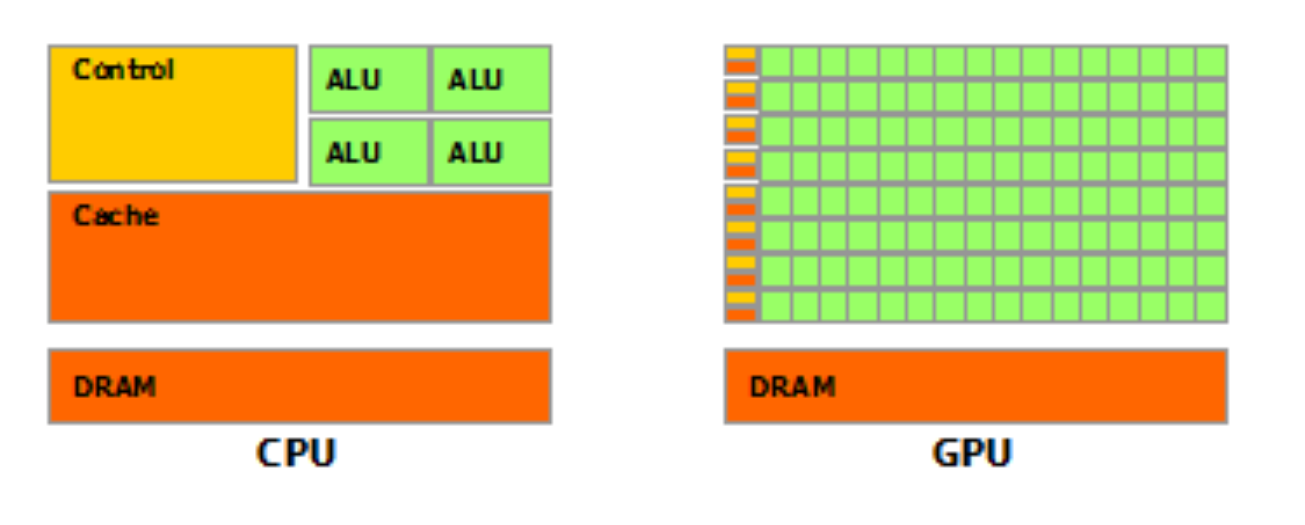
GPUs are typically faster than CPUs for computation-intensive tasks that can be divided into smaller, independent tasks that can be executed concurrently. GPUs have a significantly larger number of cores compared to CPUs, allowing them to work together efficiently and share data and resources for optimal performance.
On the other hand, CPUs are designed for general-purpose computing and excel at sequential tasks where instructions are executed one at a time. They are well-suited for tasks that involve complex logic and decision-making but are less efficient for parallelizable tasks.
While GPUs are commonly used for accelerating graphics processing, such as rendering images and videos by manipulating large amounts of data, they are increasingly utilized for other computation-intensive tasks like scientific computing, machine learning, and artificial intelligence.
It is important to note that CPUs may still be more efficient for tasks that require complex logic or decision-making, and GPUs are not always the best choice.
Ways to do CUDA GPU Programming in Python
As we know, the basic approach of parallel programming using GPU is data parallelism
We do the same operations on different subsets of the same data or different processors take different slices of the data but still do the same thing
Vector, Matrix, and Tensor are usually the data types that apply to this data parallelism
Before diving deeper into the CUDA API, let’s see the basic thread hierarchy of the CUDA programming paradigm
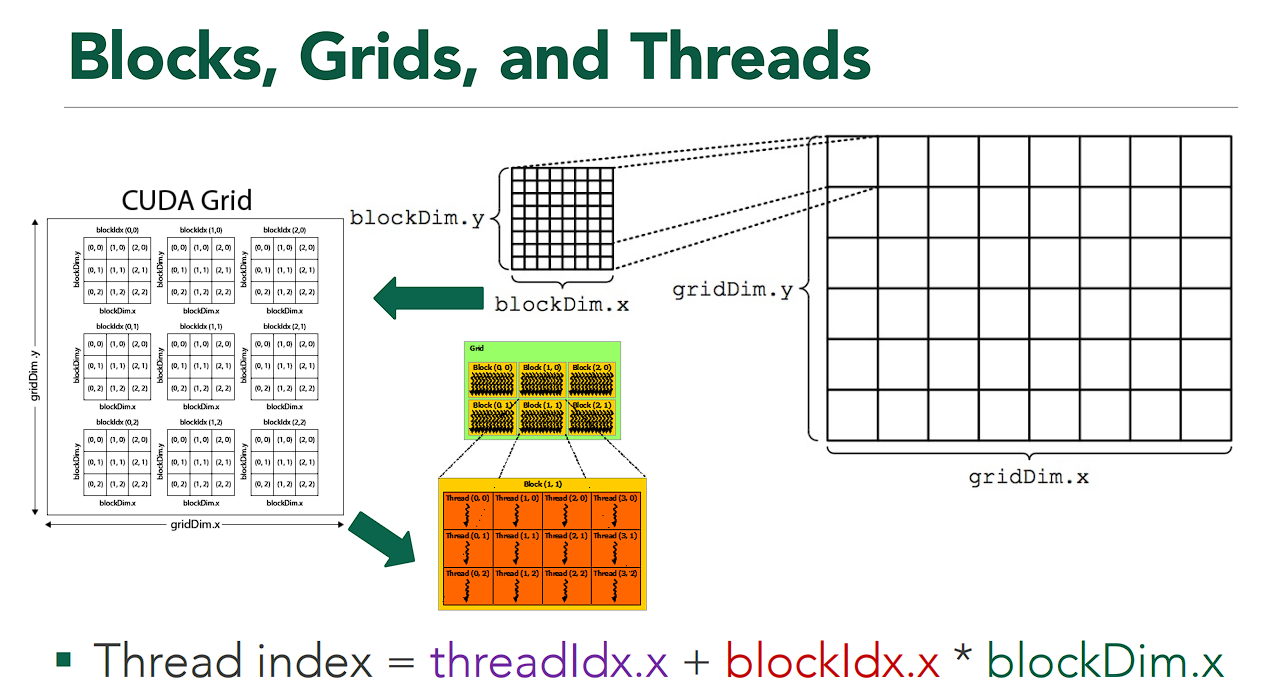
The thread hierarchy can be represented by three components:
- Thread
- Executing the CUDA code
- Having each threadIdx up to 3 dimensions
- The threadIdx is utilized to specify which part of data we want to compute on
- Block
- Organizing the group of threads
- Blocks execute independently
- Block index (blockIdx) and Block dimension (blockDim) can be indexed up to 3 dimensions
- Threads within a block can communicate and share data with each other (via shared memory)
- However, the block cannot share its data with the other blocks!
- Grid
- Group of blocks
How does CUDA work across the CPU and GPU?
- There are two terms in the communication between CPU and GPU
- CPU is called Host
- GPU is called Device
The host will act as the one that performs logic operations to obtain the data once it is ready to be processed. The host sends it to the device to perform parallel computational operations there.
To specify whether the code that we are going to run is running on the host or device, we can define all these things with CUDA Kernels. CUDA Kernels are the C/C++ code with additional syntax to determine that we are executing our code on the device. A kernel is defined using the **global** and called using «<….»> execution configuration syntax.
// Kernel definition
__global__ void VecAdd(float* A, float* B, float* C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
...
// Kernel invocation with N threads
VecAdd<<<1, N>>>(A, B, C);
...
}
Compiling CUDA strings in Python 👣
One of the libraries that can do this for us is PyCUDA
- PyCUDA
- Take strings of CUDA code and call it in Python
- It automatically manages memory; if the object goes out of its lifetime, it will automatically clean it up
- Data Transfer through In, Out, and InOut
- Wrappers for data transfer from and to GPU (host)
- Checking the errors on the CUDA code
- Metaprogramming support to find better thread numbers, etc.
C/C++ Extension (Harder way 🎣)
- PyTorch, TensorFlow, and another Deep Learning library wrap up the CUDA programming inside with the C++ extension
- nvcc Compiler for CUDA to C/C++ by NVIDIA
- nvcc will take CUDA C/C++ source code and compile the kernel to GPU assembly code
- Replacing CUDA special syntax in the C/C++ code
- Using Cython to generate a C++ class, then using setup tools to link everything
- Or using Pybind to bind the Python code with the C++
- We can manage our memory manually (for expert users)
- There is also a compiler that can tell whether there is an error or not in the CUDA code!
Drop-in replacement (Where the magic comes 🧙🏻♂️!)
If you don’t want to bother with the lower level of CUDA implementation, as you might already know, we have magic that can save us a lot of time! Yes, in Python, there are several libraries that will do magic for dealing with CUDA programming; we just need to specify the JIT (Just In Time) decorators in Numba or merely import cuPy as cp instead of import numpy as np. These are the libraries that support drop-in replacement in the Python language:
References
- https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
- https://developer.nvidia.com/blog/cuda-refresher-reviewing-the-origins-of-gpu-computing/
- **William Horton, CUDA in your Python: Effective Parallel Programming on the GPU, PyCon 2019**
- Parallel Programming for Multicore and Cluster Systems, CSC447, https://harmanani.github.io/classes/csc447/Notes/Lecture15.pdf
Written with StackEdit.