Transformer (트랜스포머)
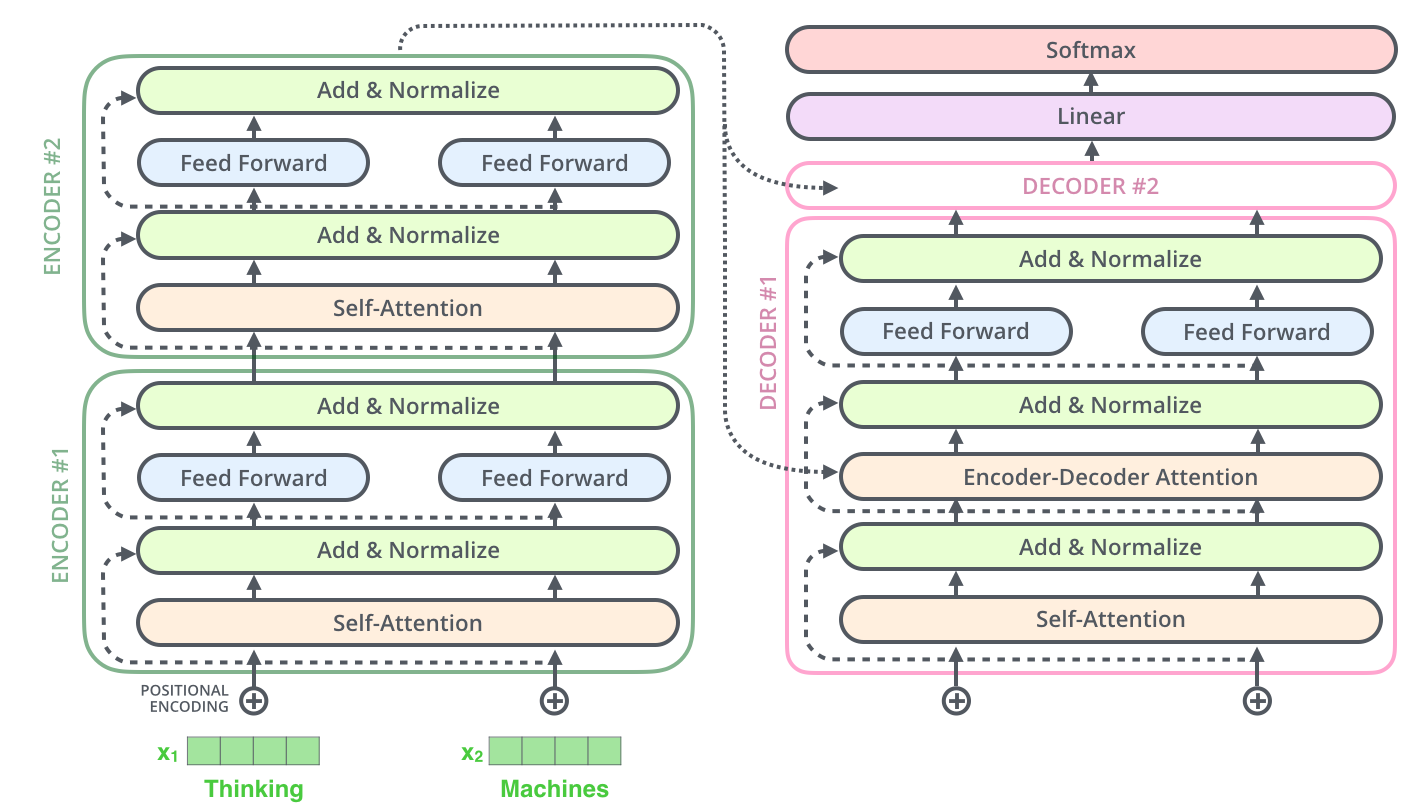 Transformers Architecture, from Illustrated Transformer
Transformers Architecture, from Illustrated Transformer
The Transformer model ditches the need for recurrent and convolution layers in sequence modeling entirely by relying solely on attention mechanisms.
The transformer model has two components: the encoder and the decoder, which is similar to the Seq2Seq model.
For the input and output, in its “Attention is All You Need” paper, the transformer utilizes the embedding layers.
Layers inside the transformer 🤖
Positional Encoding ⌖
- Order in the sequence is important, as the order of the data matters to the context.
“sequence model is awesome.”→ Looks good“sequence model awesome is.”→ Looks weird
- To capture the relative or absolute position information of the sequence data, the transformer model utilizes sine and cosine functions to encode the positional information of each data point.
- The reasons to use sine and cosine functions are:
Both functions bound the encoded value between -1 and 1:which makes the model more handy to process the information.The periodicity of the functions:it ensures that the encoding stays relevant for different sequence lengths.To avoid confusion for the model:we can use multiple frequencies to ensure that the different positions have distinct and unique encoded values. This also helps to prevent confusion because of the aliasing.Easy to extrapolate:for the long sequences, which might be longer than the data length that the model encountered during training, both functions allow the model to easily extrapolate for the longer sequences.
Self-Attention ‼️
- The relationship between each sequence of data is also important. In text data such as sentences, sometimes there is a word that refers to or relates to another word. If the information about the relationship between each word disappears, the data’s meaning will also change.
“We cooked the fried rice with a wok, and it smelled really good.”→“it”in this sentence refers to“fried rice"even though a wok can smell good as well, but that is not the word that word“it”refers to.
- Then, how can we give a relational context to the transformer model?
- That’s where self-attention plays a big role! (Attention is all you need)
- Self-attention helps the transformer keep track of how each piece of sequence data within input or output relates to the others, including itself.
- Self-attention has three key parts: Query (Q), Key (K), and Value (V).
Query:representing the encoded value by multiplying it with another pair of weights.Key:value representation of other data sequences, including itself, for computing the similarity with the query.- The similarity is computed through the dot product. The larger the similarity value, the more similar the data is.
- Then the similarity value goes through a Softmax layer.
Value:another value representation of each data, the function is to multiply this value representation with the similarity value that has gone through the softmax layer and sum all of them together to get the self-attention value.- From the paper, the scaling factor with the dimensions of Key in the dot product between Query and Key assists the transformer in performing better with the larger sequence data.
-
Self-attention equation from the paper:
\[\text{Attention}(Q,K,V)=\text{softmax}(\frac{QK^T}{\sqrt{d_k}})V\]
-
For each sequence of data, the set of weights inside the Query, Value, and Key will be reused, so it will be the same. Due to this good characteristic, the transformer has the advantage that it can be parallelized.
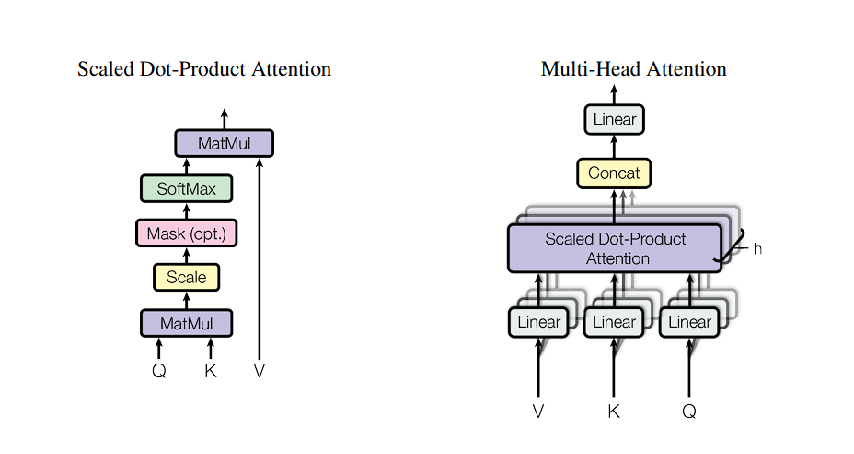
Multi-Head Attention, from Attention Is All You Need
- We can also think of self-attention as a cell. By stacking each self-attention cell with its own set of weights and running it in parallel. Therefore, if the sequence data gets more complex, it will ensure that the model can capture more complex and richer relationships between each sequence data. The stacking of multiple self-attention cells is called
“Multi-Head Attention”.- The default amount in its original paper is 8 self-attention cells for one multi-head attention layer.
Residual Connections 🛣️
- The skip residual connection makes the transformer more handy to train the more complex model.
Encoder-Decoder Attention 🌉
- To keep track of the relationship between input and output phrases and ensure that the important sequence data is not lost during inference, the transformer has a layer named encoder-decoder attention.
- For instance, we have a sequence of words:
“Don’t throw the trash anywhere”. There is an important word in that sentence:"Don't". If the decoder doesn’t track this word during translation, the result and meaning can be utterly different. - The calculation mechanism is based on self-attention. It also calculates the similarity to get the relationship between sequence data, but the similarity calculation is now focused on how the output sequence data (decoder part) is related to each of the input sequence data (encoder part).
- As in the self-attention cell, each encoder-decoder attention cell keeps the same shared weight value, which makes the transformer flexible with different lengths of inputs and outputs. And it can be stacked as well.
Norm Layer ➗
- As the size of the input and output sequence data becomes longer and larger, the scalability problem arises. Thus, to scale and make the transformer work with that longer sequence, we need to normalize the values after every step of the layer by adding the norm layer.
Additional Layers (Fully Connected Layers) 📚
- To make the transformer able to fit more complicated data by adding more parameters (weights and biases), we can add the Feed Forward or Fully Connected Layers to both the encoder and decoder parts.
References
- Vaswani, Ashish, et al. “Attention is all you need.” Advances in neural information processing systems 30 (2017)
- StatQuest, “Transformer Neural Networks, ChatGPT’s foundation, Clearly Explained!!!”
- The Illustrated Transformers, https://jalammar.github.io/illustrated-transformer/
Written with StackEdit.